Publications
2025
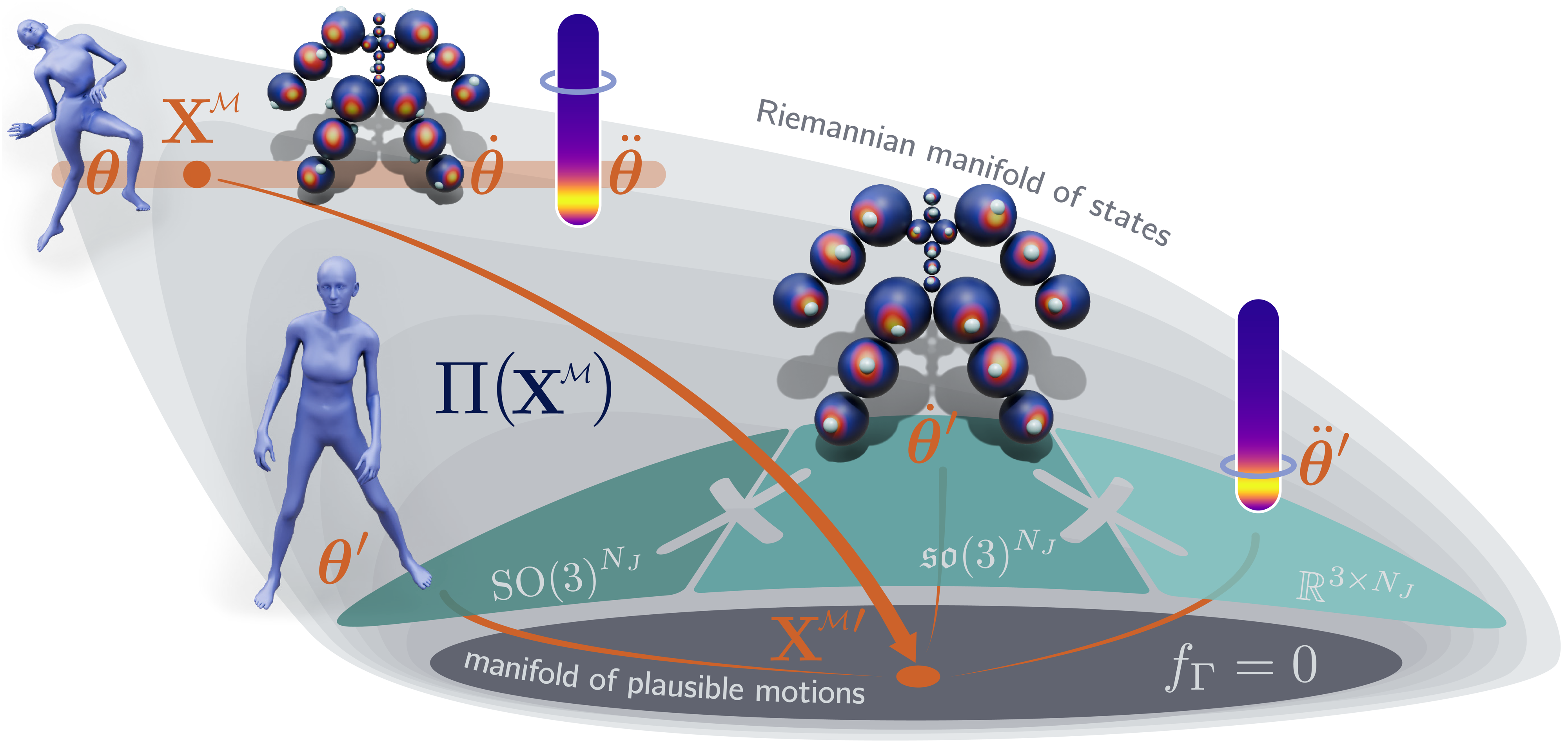
Geometric Neural Distance Fields for Learning Human Motion Priors
Zhengdi Yu, Simone Foti, Linguang Zhang, Amy Zhao, Cem Keskin, Stefanos Zafeiriou, Tolga Birdal
arXiv 2025
"a novel 3D generative human motion prior that enables robust, temporally consistent, and physically plausible 3D motion recovery."
Zhengdi Yu, Simone Foti, Linguang Zhang, Amy Zhao, Cem Keskin, Stefanos Zafeiriou, Tolga Birdal
arXiv 2025
"a novel 3D generative human motion prior that enables robust, temporally consistent, and physically plausible 3D motion recovery."
- project page
- paper
-
abstract
We introduce Neural Riemannian Motion Fields (NRMF), a novel 3D generative human motion prior that enables robust, temporally consistent, and physically plausible 3D motion recovery. Unlike existing VAE or diffusion-based methods, our higher-order motion prior explicitly models the human motion in the zero level set of a collection of neural distance fields (NDFs) corresponding to pose, transition (velocity), and acceleration dynamics. Our framework is rigorous in the sense that our NDFs are constructed on the product space of joint rotations, their angular velocities, and angular accelerations, respecting the geometry of the underlying articulations. We further introduce: (i) a novel adaptive-step hybrid algorithm for projecting onto the set of plausible motions, and (ii) a novel geometric integrator to "roll out" realistic motion trajectories during test-time-optimization and generation. Our experiments show significant and consistent gains: trained on the AMASS dataset, NRMF remarkably generalizes across multiple input modalities and to diverse tasks ranging from denoising to motion in-betweening and fitting to partial 2D / 3D observations.
- source code
-
bibtex
@article{yu2025nrmf, title={Geometric Neural Distance Fields for Learning Human Motion Priors}, author={Yu, Zhengdi and Foti, Simone and Zhang, Linguang and Zhao, Amy and Keskin, Cem and Zafeiriou, Stefanos and Birdal, Tolga}, journal={arXiv preprint arXiv:2509.09667}, year={2025} }

Dyn-HaMR: Recovering 4D Interacting Hand Motion from a Dynamic Camera
Zhengdi Yu, Stefanos Zafeiriou, Tolga Birdal
CVPR 2025 Highlight (Top 13.5% of accepted papers selected)
"the first approach to reconstruct 4D global hand motion from monocular videos recorded by dynamic cameras in the wild"
Zhengdi Yu, Stefanos Zafeiriou, Tolga Birdal
CVPR 2025 Highlight (Top 13.5% of accepted papers selected)
"the first approach to reconstruct 4D global hand motion from monocular videos recorded by dynamic cameras in the wild"
- project page
- paper
-
abstract
We propose Dyn-HaMR, to the best of our knowledge, the first approach to reconstruct 4D global hand motion from monocular videos recorded by dynamic cameras in the wild. Reconstructing accurate 3D hand meshes from monocular videos is a crucial task for understanding human behaviour, with significant applications in augmented and virtual reality (AR/VR). However, existing methods for monocular hand reconstruction typically rely on a weak perspective camera model, which simulates hand motion within a limited camera frustum. As a result, these approaches struggle to recover the full 3D global trajectory and often produce noisy or incorrect depth estimations, particularly when the video is captured by dynamic or moving cameras, which is common in egocentric scenarios. Our Dyn-HaMR consists of a multi-stage, multi-objective optimization pipeline, that factors in (i) simultaneous localization and mapping (SLAM) to robustly estimate relative camera motion, (ii) an interacting-hand prior for generative infilling and to refine the interaction dynamics, ensuring plausible recovery under (self-)occlusions, and (iii) hierarchical initialization through a combination of state-of-the-art hand tracking methods. Through extensive evaluations on both in-the-wild and indoor datasets, we show that our approach significantly outperforms state-of-the-art methods in terms of 4D global mesh recovery. This establishes a new benchmark for hand motion reconstruction from monocular video with moving cameras.
- source code
-
bibtex
@inproceedings{yu2025dynhamr, title={Dyn-HaMR: Recovering 4D Interacting Hand Motion from a Dynamic Camera}, author={Yu, Zhengdi and Zafeiriou, Stefanos and Birdal, Tolga}, booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, month = {June}, year = {2025}, }
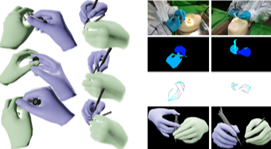
Towards Dynamic 3D Reconstruction of Hand-Instrument Interaction in Ophthalmic Surgery
Ming Hu*, Zhengdi Yu*, Feilong Tang, Kaiwen Chen, Yulong Li, Imran Razzak, Junjun He, Tolga Birdal,
Kaijing Zhou, Zongyuan Ge (* equal contribution)
NeurIPS 2025 Spotlight
"the first extensive RGB-D dynamic 3D reconstruction dataset for ophthalmic surgery"
Ming Hu*, Zhengdi Yu*, Feilong Tang, Kaiwen Chen, Yulong Li, Imran Razzak, Junjun He, Tolga Birdal,
Kaijing Zhou, Zongyuan Ge (* equal contribution)
NeurIPS 2025 Spotlight
"the first extensive RGB-D dynamic 3D reconstruction dataset for ophthalmic surgery"
- project page
- paper
-
abstract
Accurate 3D reconstruction of hands and instruments is critical for vision-based analysis of ophthalmic microsurgery, yet progress has been hampered by the lack of realistic, large-scale datasets and reliable annotation tools. In this work, we introduce OphNet-3D, the first extensive RGB-D dynamic 3D reconstruction dataset for ophthalmic surgery, omprising 41 sequences from 40 surgeons and totaling 7.1 million frames, with fine-grained annotations of 12 surgical phases, 10 instrument categories, dense MANO hand meshes, and full 6-DoF instrument poses. To scalably produce high-fidelity labels, we design a multi-stage automatic annotation pipeline that integrates multi-view data observation, data-driven motion prior with cross-view geometric consistency and biomechanical constraints, along with a combination of collision-aware interaction constraints for instrument interactions. Building upon OphNet-3D, we establish two challenging benchmarks—bimanual hand pose estimation and hand–instrument interaction reconstruction—and propose two dedicated architectures: H-Net for dual-hand mesh recovery and OH-Net for joint reconstruction of two-hand–two-instrument interactions. These models leverage a novel spatial reasoning module with weak-perspective camera modeling and collision-aware center-based representation. Both architectures outperform existing methods by substantial margins, achieving improvements of over 2mm in Mean Per Joint Position Error (MPJPE) and up to 23% in ADD-S metrics for hand and instrument reconstruction, respectively.
- source code
-
bibtex
@misc{hu2025ophnet-3d, title={Towards Dynamic 3D Reconstruction of Hand-Instrument Interaction in Ophthalmic Surgery}, author={Ming Hu and Zhendi Yu and Feilong Tang and Kaiwen Chen and Yulong Li and Imran Razzak and Junjun He and Tolga Birdal and Kaijing Zhou and Zongyuan Ge}, year={2025}, eprint={2505.17677}, archivePrefix={arXiv}, primaryClass={cs.CV}, url={https://arxiv.org/abs/2505.17677}, }
2024
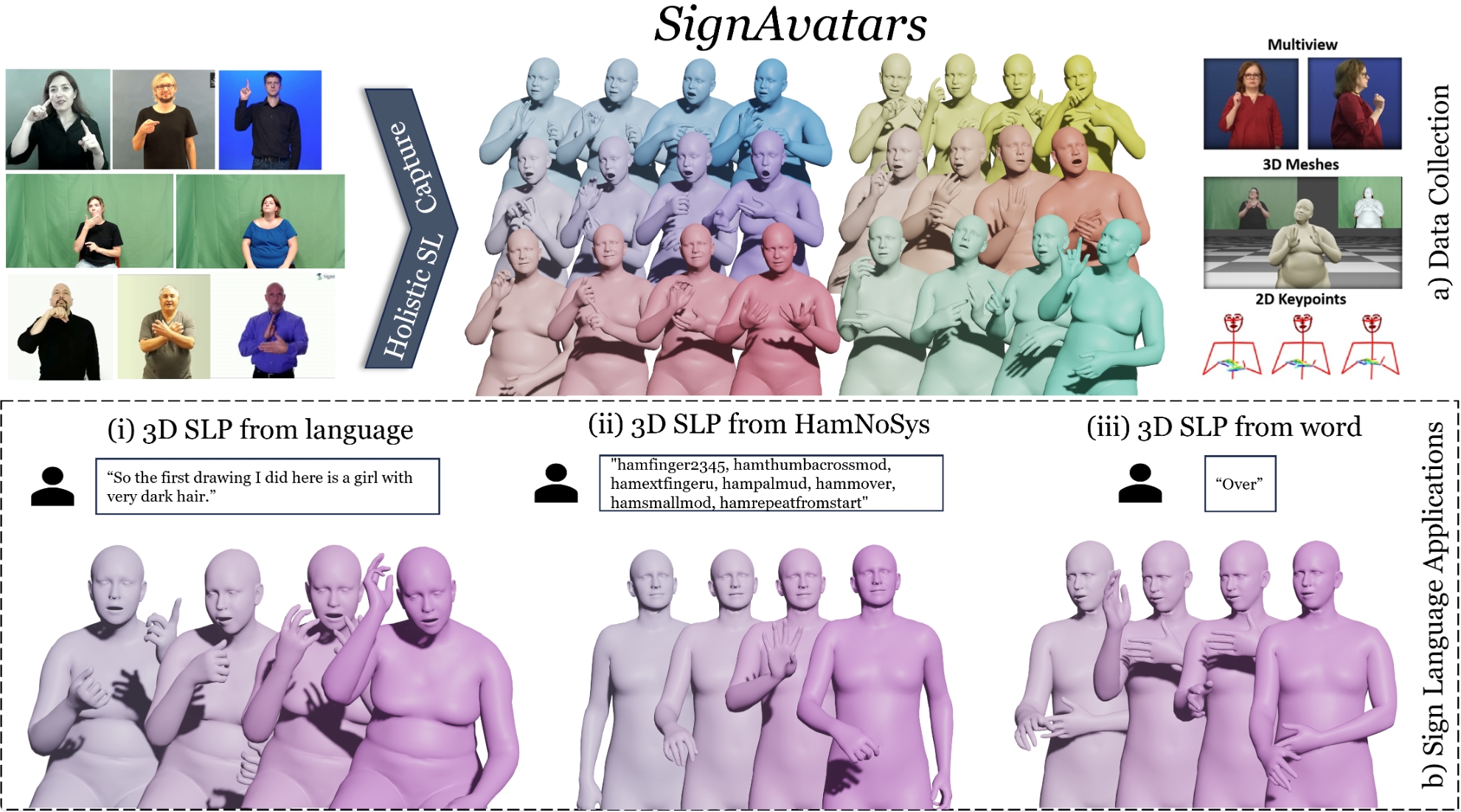
SignAvatars: A Large-scale 3D Sign Language Holistic Motion Dataset and Benchmark
Zhengdi Yu, Shaoli Huang*, Yongkang Cheng, Tolga Birdal
ECCV 2024
"the first large-scale 3D sign language holistic motion dataset and benchmark"
Zhengdi Yu, Shaoli Huang*, Yongkang Cheng, Tolga Birdal
ECCV 2024
"the first large-scale 3D sign language holistic motion dataset and benchmark"
- project page
- paper
-
abstract
We present SignAvatars, the first large-scale, multi-prompt 3D sign language (SL) motion dataset designed to bridge the communication gap for Deaf and hard-of-hearing individuals. While there has been an exponentially growing number of research regarding digital communication, the majority of existing communication technologies primarily cater to spoken or written languages, instead of SL, the essential communication method for Deaf and hard-of-hearing communities. Existing SL datasets, dictionaries, and sign language production (SLP) methods are typically limited to 2D as annotating 3D models and avatars for SL is usually an entirely manual and labor-intensive process conducted by SL experts, often resulting in unnatural avatars. In response to these challenges, we compile and curate the SignAvatars dataset, which comprises 70,000 videos from 153 signers, totaling 8.34 million frames, covering both isolated signs and continuous, co-articulated signs, with multiple prompts including HamNoSys, spoken language, and words. To yield 3D holistic annotations, including meshes and biomechanically-valid poses of body, hands, and face, as well as 2D and 3D keypoints, we introduce an automated annotation pipeline operating on our large corpus of SL videos. SignAvatars facilitates various tasks such as 3D sign language recognition (SLR) and the novel 3D SL production (SLP) from diverse inputs like text scripts, individual words, and HamNoSys notation. Hence, to evaluate the potential of SignAvatars, we further propose a unified benchmark of 3D SL holistic motion production. We believe that this work is a significant step forward towards bringing the digital world to the Deaf and hard-of-hearing communities as well as people interacting with them.
- source code
- dataset
-
bibtex
@inproceedings{yu2024signavatars, title={SignAvatars: A large-scale 3D sign language holistic motion dataset and benchmark}, author={Yu, Zhengdi and Huang, Shaoli and Cheng, Yongkang and Birdal, Tolga}, booktitle={Proceedings of the European Conference on Computer Vision (ECCV)}, pages={1--19}, year={2024} }

U3DS³: Unsupervised 3D Semantic Scene Segmentation
Jiaxu Liu, Zhengdi Yu, Hubert P. H. Shum, Toby P. Breckon
WACV 2024
"the first attempt towards unsupervised 3D semantic segmentation via region growing."
Jiaxu Liu, Zhengdi Yu, Hubert P. H. Shum, Toby P. Breckon
WACV 2024
"the first attempt towards unsupervised 3D semantic segmentation via region growing."
- paper
-
abstract
Contemporary point cloud segmentation approaches largely rely on richly annotated 3D training data. However, it is both time-consuming and challenging to obtain consistently accurate annotations for such 3D scene data. Moreover, there is still a lack of investigation into fully unsupervised scene segmentation for point clouds, especially for holistic 3D scenes. This paper presents \oursnospace, as a step towards completely unsupervised point cloud segmentation for any holistic 3D scenes. To achieve this, \ours leverages a generalized unsupervised segmentation method for both object and background across both indoor and outdoor static 3D point clouds with no requirement for model pre-training, by leveraging only the inherent information of the point cloud to achieve full 3D scene segmentation. The initial step of our proposed approach involves generating superpoints based on the geometric characteristics of each scene. Subsequently, it undergoes a learning process through a spatial clustering-based methodology, followed by iterative training using pseudo-labels generated in accordance with the cluster centroids. Moreover, by leveraging the invariance and equivariance of the volumetric representations, we apply the geometric transformation on voxelized features to provide two sets of descriptors for robust representation learning. Finally, our evaluation provides state-of-the-art results on the ScanNet and SemanticKITTI, and competitive results on the S3DIS, benchmark datasets.
- video
-
bibtex
@inproceedings{liu2024u3ds3, title={U3ds3: Unsupervised 3d semantic scene segmentation}, author={Liu, Jiaxu and Yu, Zhengdi and Breckon, Toby P and Shum, Hubert PH}, booktitle={Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision}, pages={3759--3768}, year={2024} } - DOI

Decomposable human motion prior for video pose estimation via adversarial training
Wenshuo Chen, Xiang Zhou, Zhengdi Yu, Weixi Gu, Kai Zhang
FICC 2024
"an adversarial framework that decomposes holistic motion priors into independent joint-wise priors"
Wenshuo Chen, Xiang Zhou, Zhengdi Yu, Weixi Gu, Kai Zhang
FICC 2024
"an adversarial framework that decomposes holistic motion priors into independent joint-wise priors"
- paper
-
abstract
Estimating human pose from video is a task that receives considerable attention due to its applicability in numerous 3D fields. The complexity of prior knowledge of human body movements poses a challenge to neural network models in the task of regressing keypoints. In this paper, we address this problem by incorporating motion prior in an adversarial way. Different from previous methods, we propose to decompose holistic motion prior to joint motion prior, making it easier for neural networks to learn from prior knowledge thereby boosting the performance on the task. We also utilize a novel regularization loss to balance accuracy and smoothness introduced by motion prior. Our method achieves 9% lower PA-MPJPE and 29% lower acceleration error than previous methods tested on 3DPW. The estimator proves its robustness by achieving impressive performance on in-the-wild dataset.
-
bibtex
@inproceedings{chen2024decomposed, title={Decomposed Human Motion Prior for Video Pose Estimation via Adversarial Training}, author={Chen, Wenshuo and Zhou, Xiang and Yu, Zhengdi and Gu, Weixi and Zhang, Kai}, booktitle={Future of Information and Communication Conference}, pages={516--525}, year={2024}, organization={Springer} }
2023

ACR: Attention Collaboration-based Regressor for Arbitrary Two-Hand Reconstruction
Zhengdi Yu, Shaoli Huang*, Chen Fang, Toby P. Breckon, Jue Wang
CVPR 2023
"the first one-stage arbitrary hand reconstruction method using only a monocular RGB image as input."
Zhengdi Yu, Shaoli Huang*, Chen Fang, Toby P. Breckon, Jue Wang
CVPR 2023
"the first one-stage arbitrary hand reconstruction method using only a monocular RGB image as input."
- project page
- paper
- supplemental material
-
abstract
Fiducial markers have been playing an important role in augmented reality (AR), robot navigation, and general applications where the relative pose between a camera and an object is required. Here we introduce TopoTag, a robust and scalable topological fiducial marker system, which supports reliable and accurate pose estimation from a single image. TopoTag uses topological and geometrical information in marker detection to achieve higher robustness. Topological information is extensively used for 2D marker detection, and further corresponding geometrical information for ID decoding. Robust 3D pose estimation is achieved by taking advantage of all TopoTag vertices. Without sacrificing bits for higher recall and precision like previous systems, TopoTag can use full bits for ID encoding. TopoTag supports tens of thousands unique IDs and easily extends to millions of unique tags resulting in massive scalability. We collected a large test dataset including in total 169,713 images for evaluation, involving in-plane and out-of-plane rotation, image blur, different distances and various backgrounds, etc. Experiments on the dataset and real indoor and outdoor scene tests with a rolling shutter camera both show that TopoTag significantly outperforms previous fiducial marker systems in terms of various metrics, including detection accuracy, vertex jitter, pose jitter and accuracy, etc. In addition, TopoTag supports occlusion as long as the main tag topological structure is maintained and allows for flexible shape design where users can customize internal and external marker shapes. Code for our marker design/generation, marker detection, and dataset are available at https://herohuyongtao.github.io/publications/publications/acr/.
- source code
-
bibtex
@inproceedings{yu2023acr, title = {ACR: Attention Collaboration-based Regressor for Arbitrary Two-Hand Reconstruction}, author = {Yu, Zhengdi and Huang, Shaoli and Chen, Fang and Breckon, Toby P. and Wang, Jue}, booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, month = {June}, year = {2023} }
2022
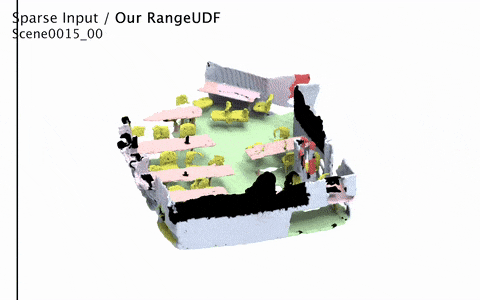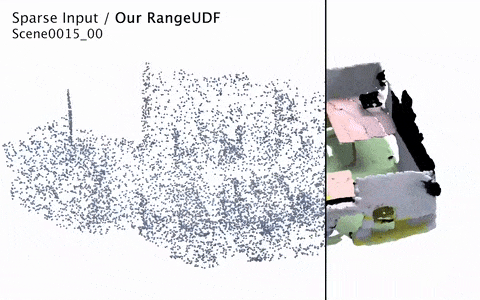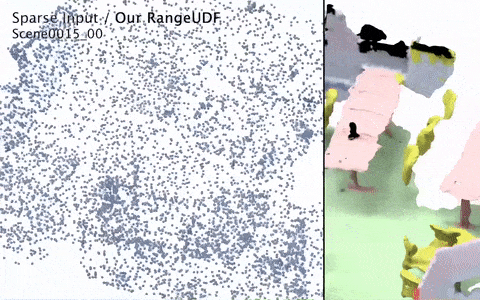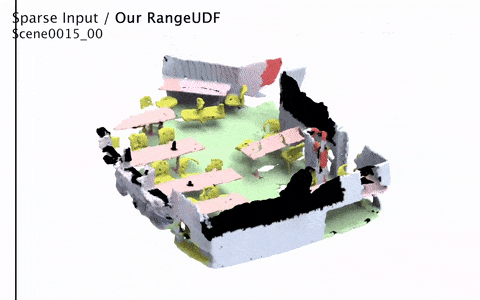
RangeUDF: Semantic Surface Reconstruction from 3D Point Clouds
Bing Wang, Zhengdi Yu, Bo Yang, Jie Qin, Toby P. Breckon, Lin Shao, Niki Trigoni, Andrew Markham
arXiv 2023
"a new implicit network to recover the geometry and semantics of continuous 3D scene surfaces from point clouds."
Bing Wang, Zhengdi Yu, Bo Yang, Jie Qin, Toby P. Breckon, Lin Shao, Niki Trigoni, Andrew Markham
arXiv 2023
"a new implicit network to recover the geometry and semantics of continuous 3D scene surfaces from point clouds."
- project page
- paper
-
abstract
We present RangeUDF, a new implicit representation based framework to recover the geometry and semantics of continuous 3D scene surfaces from point clouds. Unlike occupancy fields or signed distance fields which can only model closed 3D surfaces, our approach is not restricted to any type of topology. Being different from the existing unsigned distance fields, our framework does not suffer from any surface ambiguity. In addition, our RangeUDF can jointly estimate precise semantics for continuous surfaces. The key to our approach is a range-aware unsigned distance function together with a surface-oriented semantic segmentation module. Extensive experiments show that RangeUDF clearly surpasses state-of-the-art approaches for surface reconstruction on four point cloud datasets. Moreover, RangeUDF demonstrates superior generalization capability across multiple unseen datasets, which is nearly impossible for all existing approaches.
- source code
-
bibtex
@article{wang2022rangeudf, title={Rangeudf: Semantic surface reconstruction from 3d point clouds}, author={Wang, Bing and Yu, Zhengdi and Yang, Bo and Qin, Jie and Breckon, Toby and Shao, Ling and Trigoni, Niki and Markham, Andrew}, journal={arXiv preprint arXiv:2204.09138}, year={2022} }
2021

P2-Net: Joint Description and Detection of Local Features for Pixel and Point Matching
Bing Wang, Changhao Chen, Zhaopeng Cui, Jie Qin, Chris Xiaoxuan Lu, Zhengdi Yu, Peijun Zhao, Zhen Dong, Fan Zhu, Niki Trigoni, Andrew Markham
ICCV 2021
"this work takes the initiative to establish fine-grained correspondences between 2D images and 3D point clouds."
Bing Wang, Changhao Chen, Zhaopeng Cui, Jie Qin, Chris Xiaoxuan Lu, Zhengdi Yu, Peijun Zhao, Zhen Dong, Fan Zhu, Niki Trigoni, Andrew Markham
ICCV 2021
"this work takes the initiative to establish fine-grained correspondences between 2D images and 3D point clouds."
- project page
- paper
-
abstract
Accurately describing and detecting 2D and 3D keypoints is crucial to establishing correspondences across images and point clouds. Despite a plethora of learning-based 2D or 3D local feature descriptors and detectors having been proposed, the derivation of a shared descriptor and joint keypoint detector that directly matches pixels and points remains under-explored by the community. This work takes the initiative to establish fine-grained correspondences between 2D images and 3D point clouds. In order to directly match pixels and points, a dual fully convolutional framework is presented that maps 2D and 3D inputs into a shared latent representation space to simultaneously describe and detect keypoints. Furthermore, an ultra-wide reception mechanism in combination with a novel loss function are designed to mitigate the intrinsic information variations between pixel and point local regions. Extensive experimental results demonstrate that our framework shows competitive performance in fine-grained matching between images and point clouds and achieves state-of-the-art results for the task of indoor visual localization.
- source code
-
bibtex
@inproceedings{wang2021p2, title={P2-net: Joint description and detection of local features for pixel and point matching}, author={Wang, Bing and Chen, Changhao and Cui, Zhaopeng and Qin, Jie and Lu, Chris Xiaoxuan and Yu, Zhengdi and Zhao, Peijun and Dong, Zhen and Zhu, Fan and Trigoni, Niki and others}, booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision}, pages={16004--16013}, year={2021} }
Thesis

3D Representation Learning for Shape Reconstruction and Understanding
MRes Thesis, Durham University, 2023
MRes Thesis, Durham University, 2023
- paper
-
abstract
The real world we are living in is inherently composed of multiple 3D objects. However, most of the existing works in computer vision traditionally either focus on images or videos where the 3D information inevitably gets lost due to the camera projection. Traditional methods typically rely on hand-crafted algorithms and features with many constraints and geometric priors to understand the real world. However, following the trend of deep learning, there has been an exponential growth in the number of research works based on deep neural networks to learn 3D representations for complex shapes and scenes, which lead to many cutting-edged applications in augmented reality (AR), virtual reality (VR) and robotics as one of the most important directions for computer vision and computer graphics.
This thesis aims to build an intelligent system with dynamic 3D representations that can change over time to understand and recover the real world with semantic, instance and geometric information and eventually bridge the gap between the real world and the digital world. As the first step towards the challenges, this thesis explores both explicit representations and implicit representations by explicitly addressing the existing open problems in these areas. This thesis starts from neural implicit representation learning on 3D scene representation learning and understanding and moves to a parametric model based explicit 3D reconstruction method. Extensive experimentation over various benchmarks on various domains demonstrates the superiority of our method against previous state-of-the-art approaches, enabling many applications in the real world. Based on the proposed methods and current observations of open problems, this thesis finally presents a comprehensive conclusion with potential future research directions. -
bibtex
@phdthesis{yu20233d, title={3D Representation Learning for Shape Reconstruction and Understanding}, author={YU, ZHENGDI}, year={2023}, school={Durham University} } - DOI